Distributed Computing Concepts
These notes give you a brief overview of concepts of distributed computing. If you are at this chapter, it is assumed that you are familiar with writing scientific code for your analysis and are able to run it locally on your machine (laptop/desktop).
For purposes of this discussion, it is important to review some terminology.
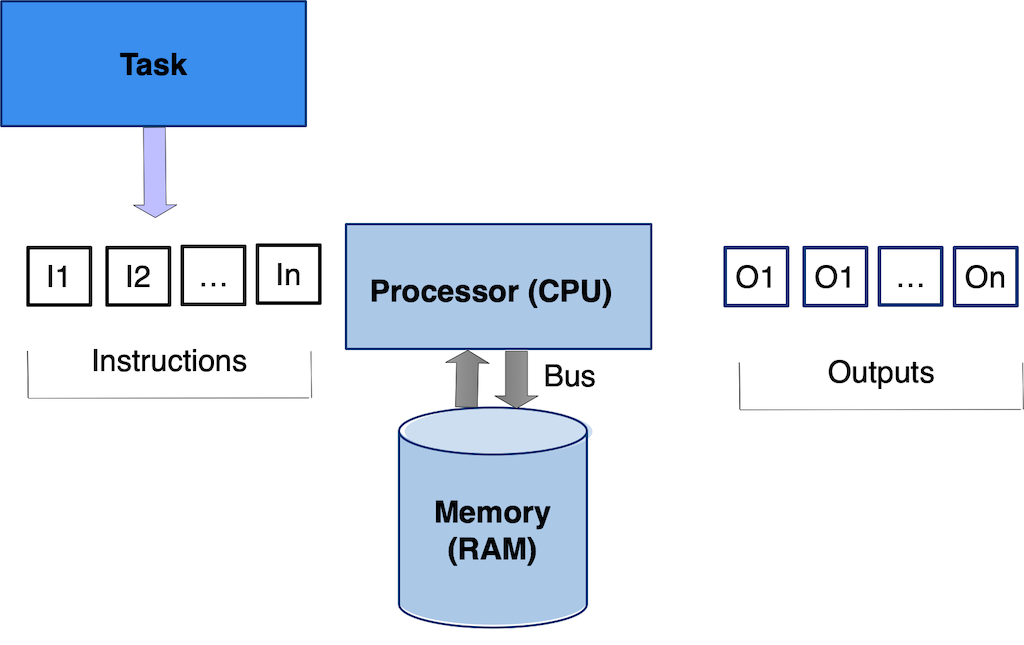
- A program or code that you run is comprised on instructions.
- A task is a program or code that you need to execute.
- Processor is any device that can process instructions. CPU’s and GPU’s are types of processors.
- CPU is the main entity in a computer that executes instructions.
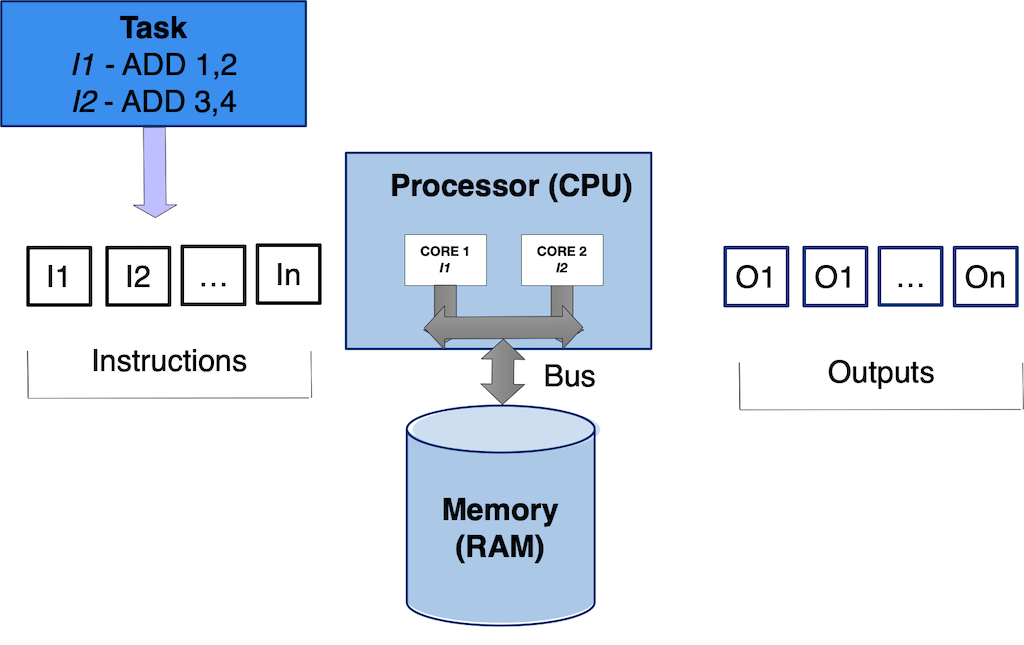
- Newer CPU’s have multiple cores. Core is a single independent processing unit within the CPU.
Serial Computing
Serial computing can be defined as executing instructions in a sequential order as laid out in your program. The order in which the instructions are executed is important and critical for correctness.
In serial computing your program runs on a single CPU/processor and speed at which your programs runs is directly proportional to the CPU’s processing power which is usually measured in Clock cycles per second (Hz). A 1 Hz CPU does 1 clock cycles per second. You can consider for discussion purposes
- 1 instruction takes 1 cycle to to get executed (not always true)
- The clock speed defines how fast your CPU can execute instructions.
- So a 1Gz CPU can execute 1 billion instructions per second!
Parallel Computing
In parallel computing you can leverage multiple CPU’s or cores to execute your program. It involves breaking down a problem into smaller, independent sub-tasks that can be processed simultaneously by multiple processors or cores. Remember modern day processors/CPU’s are now comprised of multiple cores which can act independently, allowing use to execute instructions in parallel.
Parallel computing can often be achieved by either leveraging
- Threads: Threads are light-weight sub-processes, that have access to your program global memory. Threads allow you to leverage the multiple cores on a processor/CPU. Threading needs be done carefully, as data is shared across threads and a thread can easliy modify data that another thread maybe using resulting in crashes or deadlocks.
- MPI: Message Passing Interface(MPI) allows independent processes to access a shared global memory via a message interface. This allows processes to control
what data is shared and which is private to the process. Using MPI you can either use cores on a single CPU, or also use cores across multiple CPU’s in a high performance computing cluster, where the CPU’s are connected via a high speed network such as infiniband.
Even though you can acheive serious performance gains using parallel computing, it is generally considered hard and error prone. Various reasons contribute to it such as harder debugging, memory coherence issues etc. Also as humans, we are better at thinking sequentially.
Distributed Computing
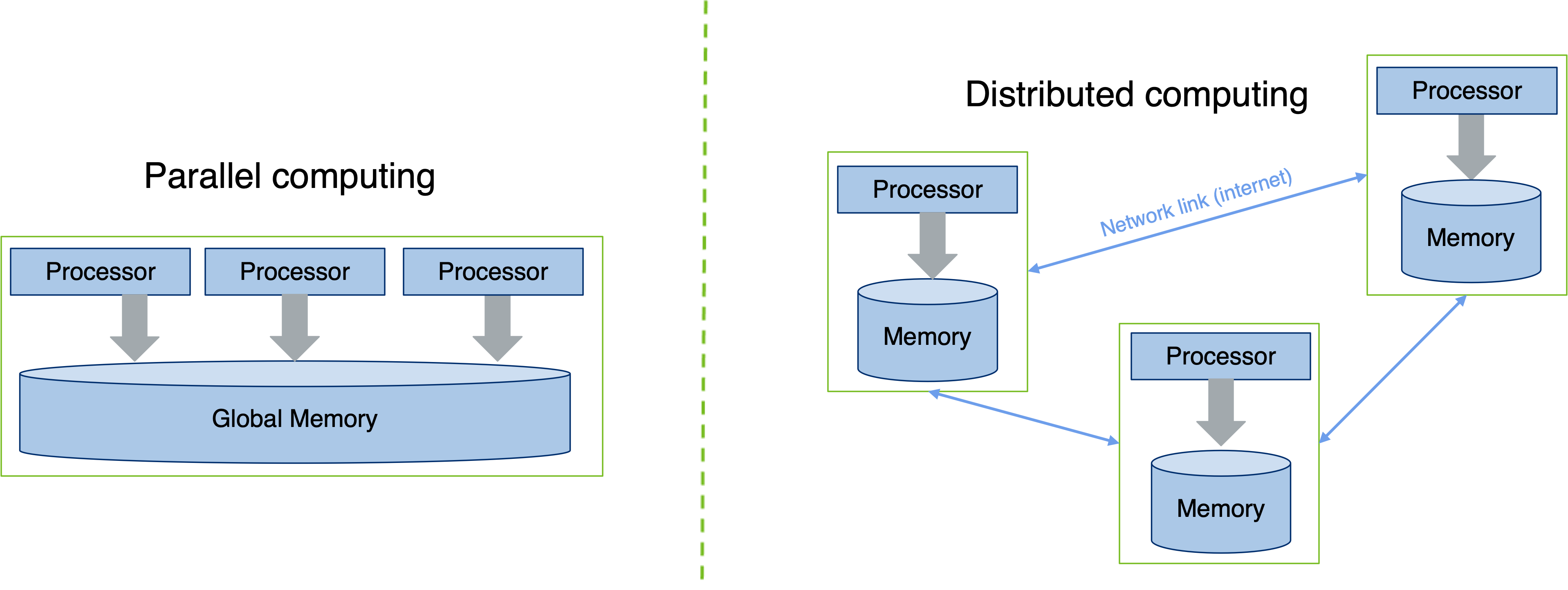
Distributed computing involves leveraging multiple computers that are connected via a local area network or a wide area network to solve a problem that you cannot solve on a local computer. For example, if you do a google search the search request gets broken down and distributed amongst various nodes to get you the results back.
Parallel and Distributed computing are often changed interchangeably. However, there are subtle differences between the two. For example, in distributed computing there is no shared memory to use. If anything, Distributed Computing should be viewed as the superset (that could include Parallel Computing).
High Performance Computing
High Performance Computing involves using high performance computing clusters or supercomputing clusters (when sufficiently large) that consist of tightly coupled compute nodes (often thousands) interconnected with a high performance shared filesystem and high speed interconnects.
A typical layout of a HPC cluster is shown below.
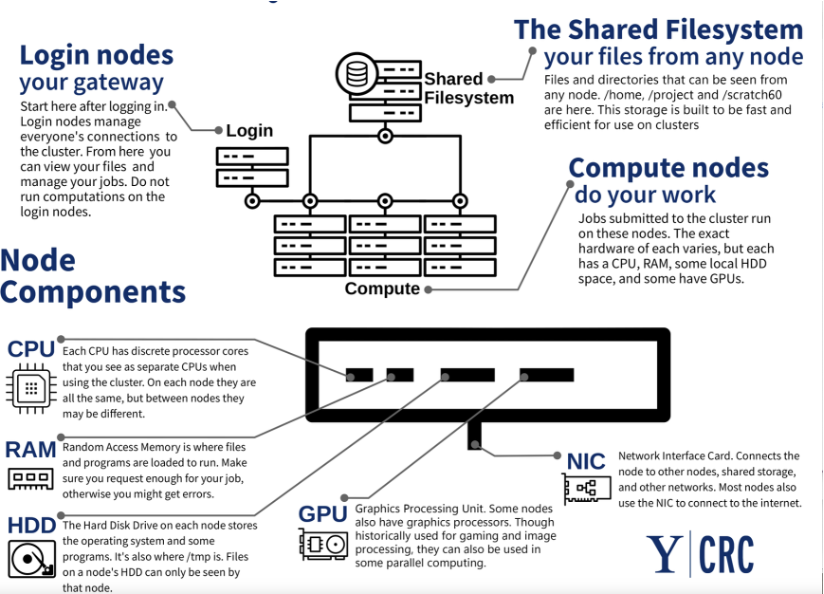
Image Credit: https://docs.ycrc.yale.edu/clusters-at-yale
Users largely use HPC resources to run parallel codes such as MPI applications. However, HPC clusters are also used to run long-running serial jobs, or jobs that require only one node.
High Throughput Computing
High Throughput Computing (HTC) involves leveraging many computing resources over long periods of time to accomplish a computational task. These computing resources are often geographically distributed and inter-connected via the internet.
HTC paradigm focused on executing a large number of tasks over a long period of time, often using distributed resources. Instead of maximizing performance for a single job (as in High Performance Computing, HPC), HTC aims to maximize the total number of jobs completed.
HTC workloads are often comprised of hundreds or thousands of serial jobs that are mainly independent or loosely coupled, and don’t need tight coupling the way HPC jobs require.
HTC focuses on increasing the overall throughput of the system by running many smaller size jobs (confined to a single core or a single) in parallel over a distributed computing infrastructure.